
Insight Blog
Agility’s perspectives on transforming the employee's experience throughout remote transformation using connected enterprise tools.
15 minutes reading time
(3048 words)
How Big Tech Collects Data Using Public Web Data Datasets

How Big Tech Collects Data Using Public Web Data Datasets
Discover how Big Tech quietly scrapes public web data datasets to profile users, train AI models and power targeted ads – and what it means for privacy.
How Big Tech Collects Data Using Public Web Data Datasets

Big Tech does not rely only on what you type into apps or search boxes.
A huge amount of intelligence comes from public web data datasets, pulled from websites, forums, reviews, job boards, open profiles, and online communities you probably interact with every day.
In fact, industry research estimates that over 80 percent of the data used by modern AI and analytics systems comes from unstructured public sources, not private databases.
This article breaks down how that data is collected at scale, why it is so valuable, and where the ethical and legal lines start to blur.
Let's be clear about what this is and what it is not.
- This is about public data, not hacking or breaches.
- This is about scale and automation, where millions of pages are processed every hour.
- This is about power and incentives, not conspiracy theories.
To put the scale into perspective, Google processes over 20 petabytes of data per day, and large AI models are trained on trillions of words, much of it sourced from the open web.
A single job board, forum, or review site can generate more behavioral insight than a private survey ever could.
When that data is collected, cleaned, combined, and analyzed across thousands of sources, it becomes an intelligence engine that smaller companies simply cannot compete with.
Most people assume public means harmless.
It is not.
Public web data datasets gain their real value when they are aggregated over time, connected to identities, and used to predict behavior at scale.
That is where the conversation stops being academic and starts becoming very real for individuals, businesses, and regulators alike.
This article strips away the mystery and explains how it actually works, in plain language, without hype and without fear mongering.
Read this article: : Top 6 AI-Powered Project Management Tools To Use In 2023
Understanding Public Data Collection Fundamentals

Understanding Public Data Collection Fundamentals
Public web data means anything visible without logging in or paying.
Amazon product prices, Twitter posts, news articles, government databases.
Companies grab this information to track trends, tweak their pricing, figure out what customers really think about products.
Just because you can see something doesn't mean you can take it though.
Three basic rules apply: data must be genuinely public, you can't violate the website's terms, and you shouldn't overwhelm their servers with requests.
The technology for ethical scraping has come a long way recently.
Companies use proxy networks to spread requests across different locations so they don't look suspicious or crash servers.
Knowing the difference between residential vs datacenter proxies matters hugely when you're collecting data at scale. Pick wrong and your whole operation fails.
What Are Public Web Data Datasets Really
At the simplest level, public web data datasets are collections of information pulled from places on the internet that anyone can access without logging in or paying.
Think websites you can browse freely, posts you can read without an account, or pages that show up in Google search results.
If a human can see it, a machine can usually collect it too.
This is where a lot of people get it wrong.
- Public does not mean harmless - A single forum post or review might seem insignificant on its own. But when millions of these are collected, analyzed, and connected together, they can reveal patterns about behavior, preferences, locations, and intent that were never obvious to the original poster.
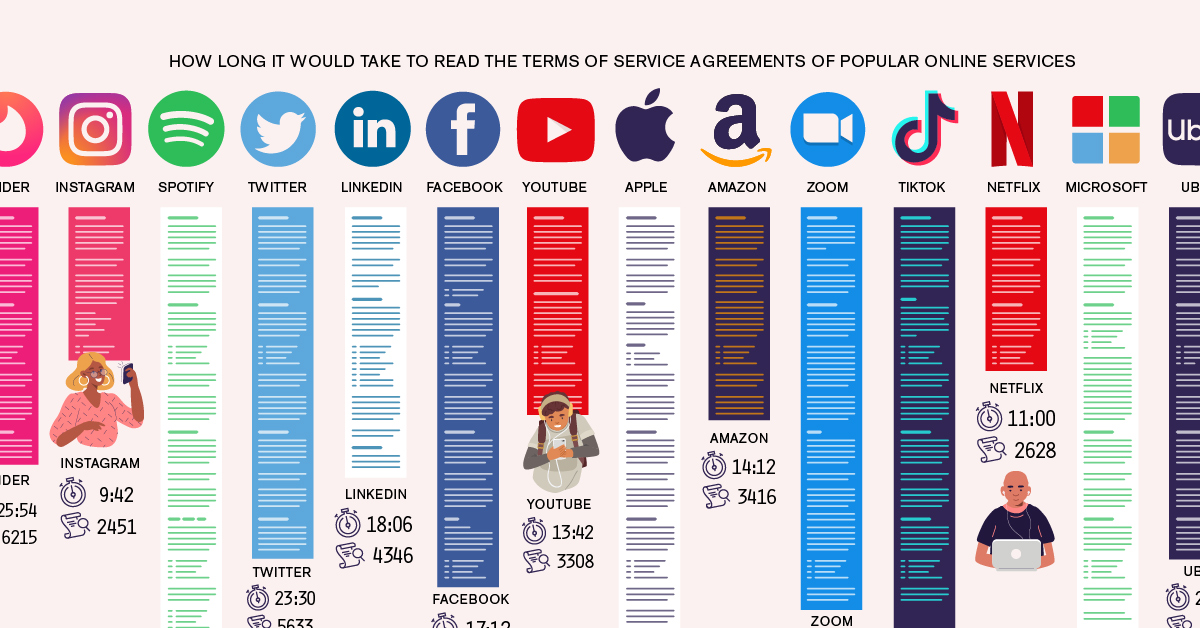
- Public does not mean consent - Most people never explicitly agree to have their content scraped, stored, and reused in massive datasets. Studies show that fewer than 25 percent of users read or understand website terms of service, yet those terms are often used to justify large-scale data collection.
- Public does not mean unregulated - Laws like GDPR and CCPA still apply to public data when it can be linked back to individuals.
Regulators have made it clear that just because data is visible does not mean it is free from responsibility or accountability.
So where does this data actually come from?
- Common sources include
- Public websites and blogs
- Online business and professional directories
- Forums and Q and A platforms
- Product reviews and rating sites
- Open social media profiles
- Government and open data portals
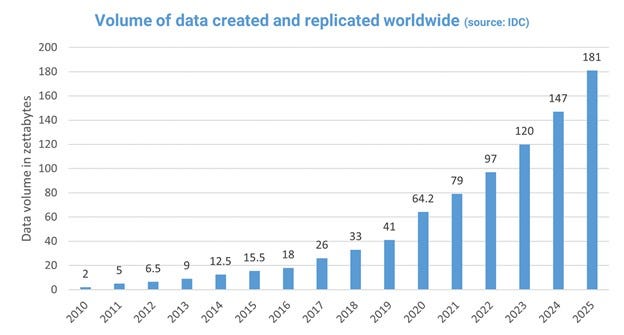
To put the scale into perspective, it is estimated that over 90 percent of the world's data has been created in the last few years, and a large portion of that lives on the public web.
Automated tools can crawl thousands of pages per second, turning everyday online activity into structured datasets almost instantly.
Here is the reality check most people miss.
Once data is indexed, scraped, cleaned, and combined, it stops being neutral. Context disappears. Intent is inferred.
Individual posts become signals in a much larger system.
That is the moment public web data datasets shift from simple information to powerful decision-making fuel.
Why Big Tech Wants Public Web Data So Badly

Why Big Tech Wants Public Web Data So Badly
Public web data datasets are not a nice-to-have for Big Tech.
They are mission-critical. Without them, most modern platforms would stall fast.
The first driver is AI and machine learning. Training large models requires enormous volumes of real-world language, images, opinions, and behavior.
Industry estimates show that over 80 percent of training data for large AI systems comes from publicly available sources, simply because there is nowhere else to get that much diverse data. Private datasets are too small, too expensive, and too narrow.
Then there is search and recommendations. Every time a platform improves search relevance or suggests content, products, or people, it is learning from patterns across the open web.
Public reviews, forum discussions, job postings, and articles help systems understand intent, context, and meaning.
This is why search engines and social platforms get smarter the longer they operate.
They never stop learning.
Predicting behavior and trends is another huge incentive. Public web data datasets make it possible to spot changes before they show up in traditional reports. Hiring spikes on job boards can signal company growth or decline.
Forum chatter can reveal product issues weeks before earnings calls. Analysts estimate that companies using large-scale web data can identify market shifts 30 to 90 days earlier than those relying on surveys or internal data alone.
Big Tech also uses public data for market intelligence and competitive analysis. Pricing pages, feature updates, customer complaints, and press releases are constantly monitored and compared.
This allows large platforms to react faster, copy smarter, and position themselves ahead of competitors who simply cannot see the full picture.
And of course, there is ad targeting and audience modeling. Public web data helps build detailed interest and intent profiles without asking users directly.
When combined with platform data, it dramatically improves ad performance. This is why targeted advertising continues to outperform broad campaigns by 2 to 3 times in conversion rates.
Now here is the uncomfortable part.
This creates a massive unfair advantage.
Smaller companies cannot match this scale. They do not have the infrastructure, the compute power, or the legal teams to collect and process billions of pages continuously. Big Tech does.
Data also compounds over time. The more data you have, the better your models get. Better models attract more users. More users generate more data. It is a feedback loop that is extremely hard to break.
And in the end, the rule is simple and brutal.
Not because they are more ethical. Not because they are smarter. But because data at scale becomes power, and public web data datasets are one of the cheapest and most effective ways to build it.
The Types of Data Big Tech Pulls From the Public Web
When people hear "public web data," they usually imagine random blog posts or the occasional review.
That is wildly understating what is actually collected.
Big Tech pulls specific, repeatable data points that become extremely powerful once they are processed at scale.
Here is what is commonly extracted.
- Names and usernames - Public profiles, author bios, forum handles, and comment sections are a goldmine. Even when real names are not used, consistent usernames can be linked across platforms. Research shows that over 60 percent of users reuse the same or similar usernames across multiple sites, making cross-platform identification far easier than most people expect.
- Job titles and company information - Job boards, LinkedIn-style profiles, press releases, and company pages reveal who works where and doing what. This data feeds hiring intelligence, sales targeting, and competitive analysis. Analysts estimate that job posting data alone predicts company growth or decline with over 70 percent accuracy when tracked over time.
- Skills and career history - Public resumes, portfolios, GitHub profiles, and certifications help build detailed skill maps. This data is heavily used for talent analytics, workforce planning, and AI-powered recruitment tools. Once collected, it rarely disappears.
- Location signals - Not always exact addresses, but city names, time zones, local events, language usage, and posting times. When combined, these signals can narrow someone's location with surprising precision. Studies show that combining just three to five location indicators is often enough to infer a user's real-world region.
- Opinions and sentiment - Reviews, comments, forum posts, and social replies are continuously analyzed for sentiment. This helps platforms understand brand perception, political leanings, and emerging controversies. Sentiment analysis tools now operate with over 85 percent accuracy in many commercial use cases.
- Buying intent signals - Product comparisons, questions like "best tool for," pricing page visits, and feature discussions all indicate intent. This data is extremely valuable for advertising and sales models because it predicts action, not just interest. Intent-based targeting consistently delivers 2 to 3 times higher conversion rates than generic audience targeting.
- Network and relationship mapping - Who replies to whom, who mentions who, and who appears together across platforms. This creates influence maps and relationship graphs. Even without private messages, public interactions reveal social and professional networks at scale.
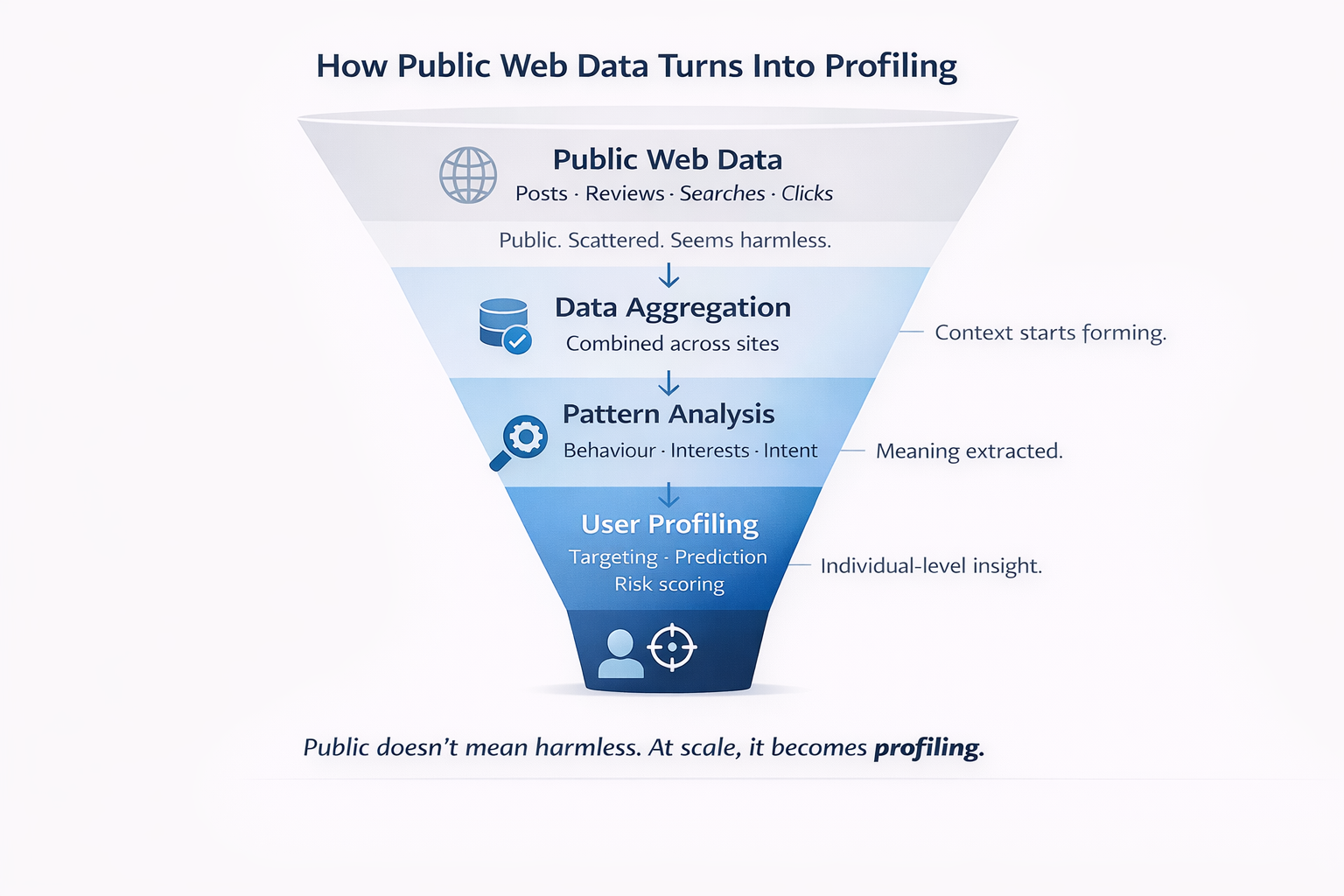
Now here is the part that actually matters.
The real risk is not the data itself. It is the combination of datasets.
- A job title alone is harmless.
- A username alone is forgettable.
- A review alone is just an opinion.
But when job history, location signals, opinions, and networks are merged, they form a persistent profile that can outlive context, intent, and accuracy.
Errors get locked in. Old data keeps influencing decisions. People become patterns rather than individuals.
This is why public web data datasets stop being neutral once they are aggregated.
The danger is not that the data exists.
The danger is that it is connected, permanent, and scalable, often without the knowledge of the people who created it.
Legal Frameworks Governing Data Collection
Here is the uncomfortable truth.
Big Tech does not collect public web data datasets in a legal vacuum. There are rules. The problem is that those rules were not designed for the scale, speed, and automation we see today.
At a high level, most data laws focus on how data is used, not just where it comes from. That means public data can still be regulated if it can be linked to a person, profile, or behavior.
GDPR and the European Standard
The General Data Protection Regulation is the toughest benchmark globally.
Under GDPR, personal data remains protected even if it is publicly available. Names, usernames, job titles, photos, and online identifiers can all fall under its scope.
- Key points that matter
- Data must have a lawful basis for processing
- Purpose limitation still applies
- Data minimization is required
- Individuals retain rights to access, correction, and erasure
Regulators have repeatedly stated that scraping public websites does not automatically make processing lawful. Fines back this up.
Since GDPR came into force, regulators have issued over €4 billion in penalties, often tied to misuse or overreach in data collection.
CCPA and CPRA in the United States
In the US, the California Consumer Privacy Act and its successor, the CPRA, take a different but still powerful approach.
These laws give consumers rights over how their data is collected, shared, and sold, even when the data is public.
- What businesses must do
- Disclose data collection practices clearly
- Allow users to opt out of data selling or sharing
- Honor deletion requests
- Limit data retention
With penalties reaching $7,500 per intentional violation, large-scale scraping without controls can turn into a serious financial risk very quickly.
Platform Terms and Website Policies
This is where many companies think they are safe. They are not.
Website terms of service, robots.txt files, and API usage rules often prohibit scraping or automated access. Ignoring these terms can lead to:- Contractual disputes
- Civil litigation
- IP blocking and service bans
- Reputational damage
Several high-profile court cases have made it clear that bypassing technical or contractual safeguards can cross legal lines, even when data is technically public.
Copyright and Database Rights
Not all public web data is free to reuse. Content like articles, images, and structured databases may be protected under copyright or database rights, particularly in the EU.
Reusing content at scale without transformation or permission can trigger legal action, regardless of public availability.
The Reality Check
Here is the gap.
Most laws were written when data collection was slower, smaller, and human-driven.
Today, automated systems can collect millions of records per hour. That creates gray areas that Big Tech often exploits while regulators struggle to keep up.
Being technically legal is not the same as being safe.
The companies that survive long term are the ones that- Document data sources
- Respect user rights
- Limit unnecessary collection
- Prepare for audits and enforcement
Public web data datasets are powerful, but mishandling them is one of the fastest ways to invite regulatory attention, fines, and long-term trust damage.
Risks and Consequences People Rarely Talk About
Most conversations about public web data datasets focus on whether collection is legal. That misses the real issue.
The damage usually shows up later and hits people who never realized their data was being reused at scale.
The biggest risks are straightforward.
- Bias gets baked in - Public web data reflects real-world bias. When models train on it, those biases scale fast. Studies show poorly balanced datasets can amplify bias by up to 40 percent.
- Old data never disappears - People change, but scraped data does not. Research suggests around 20 percent of public web data used commercially is outdated or inaccurate, yet it still influences decisions.
- Data spreads beyond control - Once collected, data is often licensed or resold. Each transfer increases the risk of misuse. Control is usually lost after the first handoff.
- Surveillance becomes normal - Constant monitoring of public behavior slowly shifts expectations. What once felt invasive becomes routine simply because it is widespread.
- Reputation damage scales - Algorithms do not forget. One post or comment can follow someone for years, stripped of context and multiplied across systems.
Here is the bottom line.
Most people are not trying to create a permanent data trail. They are just participating online.
But with public web data datasets, a single moment can outlive its context, becoming searchable, portable, and influential long after it should have faded.
What Businesses and Individuals Should Do About It
Public web data datasets are not going away.
You cannot opt out of the internet, but you can reduce risk by acting deliberately.
The biggest mistake people and companies make is assuming that public data is automatically safe or insignificant.
Once data is collected at scale, intent and context stop mattering. Discipline does.
What Individuals Should Do
The goal is not to disappear online. It is to reduce long-term exposure without changing how you live or work.
- Pause before posting and assume anything public could resurface years later in a dataset you never agreed to
- Avoid using the same username, real name, job title, and location across multiple platforms
- Treat public profiles, comments, and reviews as searchable and scrapable by default
- Assume deletion does not guarantee removal due to archives, screenshots, and scraped copies
A small shift in how you publish publicly can significantly reduce how easily your identity is tracked and reused.
What Businesses Should Do
For businesses, poor data discipline creates real legal, financial, and reputational risk.
This is where mistakes get expensive.
- Maintain a clear record of where every dataset comes from and how it was collected
- Avoid scraping practices that bypass platform rules, robots policies, or technical safeguards
- Work only with data providers who can clearly explain consent assumptions and collection methods
- Document data provenance so usage can be justified during audits or complaints
- Collect only the data required to deliver value and nothing more
The less unnecessary data you hold, the smaller your exposure when something goes wrong.
The bottom line is simple. Individuals reduce risk through awareness. Businesses reduce risk through discipline.
Public web data datasets are powerful, but treating them casually is one of the fastest ways to lose trust, trigger scrutiny, or both.
Read this article: : Top 6 AI-Powered Project Management Tools To Use In 2023
Wrapping up
Public web data datasets are not going away, and pretending otherwise is a waste of time.
Big Tech will keep collecting, refining, and monetizing them because the incentives are enormous and the technology makes it cheap to do at scale. This is now baked into how the modern internet works.
The real issue is not whether the data is public.
That debate is largely settled. The real question is whether the way this data is collected, combined, and used aligns with what people reasonably expect when they post something online. Right now, there is a clear gap between visibility and understanding, and that gap is where trust breaks down.
For individuals, awareness is the only real defense. For businesses, responsibility and restraint are no longer optional.
As regulation tightens and scrutiny increases, the winners will not be the companies that collect the most data, but the ones that can clearly justify why they collect it and how they use it.
Public web data datasets are powerful.
Used carefully, they can create insight and value. Used carelessly, they erode trust and invite backlash.
The difference is not technology. It is intent, discipline, and accountability.
Most Popular Posts

Effective communication among team members is vital for the productivity and success of any organization. Surprisingly, 60% of companies lack a long-term internal communication strategy, which p...


Businesses thrive on communication for efficiency, productivity and accomplishment. When the right information is passed from the right designation in the organization, it promotes positivity an...
Categories
Blog
(3006)
Business Management
(380)
Employee Engagement
(225)
Digital Transformation
(192)
Growth
(143)
Intranets
(137)
Remote Work
(63)
Sales
(53)
Collaboration
(48)
Customer Experience
(30)
Culture
(30)
Project management
(29)
Knowledge Management
(28)
Leadership
(20)
Comparisons
(9)
News
(1)

Related Posts

Walk into almost any workplace today and you'll find employees juggling a growing number of tools. One platform for chat, another for project management, a separate HR system, multiple document repositories, and countless email chains just to g...

Organizations spend millions of dollars each year trying to improve employee engagement, encourage innovation, and build stronger workplace cultures. Yet many still rely on annual surveys to understand what employees are thinking. The pro...

Hey, let's talk about something that's becoming a real game-changer for teams working far from reliable cell service—satellite messengers. If you've ever wondered how people stay connected in the middle of nowhere, this is it. Satellite messeng...

Modern manufacturers generate more data than ever before. Production systems, ERP platforms, HR software, maintenance applications, quality management tools, communication platforms, and manufacturing data integration tools all create valuable ...

Choosing the right project management certification can significantly impact your career, earning potential, and leadership opportunities—but choosing the wrong one could cost you hundreds of dollars, months of study time, and missed career opportuni...


Jill Romford
I am a digital nomad, lover of exploring new places and making friends.
I love to travel and I love the internet. I take pictures of my travels and share them on the internet using Instagram.
Traveler, entrepreneur, and community builder. I share my insights on digital marketing and social media while inspiring you to live your fullest life.
Ready to learn more? 👍
One platform to optimize, manage and track all of your teams. Your new digital workplace is a click away. 🚀
Free for 14 days, no credit card required.