
Insight Blog
Agility’s perspectives on transforming the employee's experience throughout remote transformation using connected enterprise tools.
27 minutes reading time
(5350 words)
What Is a Data Annotation Company? Why Data Annotation Is Critical in 2026

What Is a Data Annotation Company? Why Data Annotation Is Critical in 2026
What is data annotation? Learn what a data annotation company does, how AI annotation works, and why data annotation is critical for the digital workplace in 2026.
What Is a Data Annotation Company? Why Data Annotation Is Critical in 2026

Let's keep this simple, because this topic gets overcomplicated fast.
What is data annotation?
It's the process of labeling raw data—text, images, audio, or video—so machines can understand what they're looking at. Without that context, AI isn't "intelligent." It's just making educated guesses.
And here's the part most people miss: AI systems don't usually fail because the model is weak. They fail because the data underneath them is poorly annotated.
According to Gartner, poor data quality—including inaccurate or inconsistent labeling—costs organizations an average of $12.9 million per year in operational inefficiencies and failed initiatives. When annotations are wrong, model accuracy drops fast, no matter how advanced the algorithm claims to be.
Accuracy isn't the only issue either. Security matters just as much.
IBM's Cost of a Data Breach Report shows that breaches involving AI training data or analytics pipelines take over 270 days to identify and contain on average, largely because sensitive data is often copied, labeled, and redistributed during annotation workflows.
That's why enterprise-grade data annotation companies now focus as much on secure handling, access controls, and compliance as they do on labeling accuracy.
This becomes even more critical in 2026 because AI is no longer experimental—it's embedded directly into the digital workplace.
AI assistants, automated document processing, intelligent search, and predictive analytics all rely on annotated data behind the scenes. If that annotation isn't accurate or secure, the AI doesn't just underperform—it creates risk.
The reality is simple: behind every AI feature that works reliably in the real world, there's disciplined, high-quality data annotation doing the unglamorous work.
Skip that foundation, and your AI might look impressive in demos—but it won't survive real users, real data, or real scrutiny.
● Key Takeaways: What Is a Data Annotation Company?
- Data annotation is the foundation of reliable AI, turning raw data into structured inputs machines can actually learn from.
- A data annotation company does more than label data—it enforces accuracy, consistency, bias control, and quality assurance at scale.
- AI annotation speeds up labeling, but human oversight remains essential for context, edge cases, and high-risk data.
- Accuracy and security are inseparable in modern annotation workflows, especially when handling sensitive or regulated data.
- Poor annotation leads to unreliable AI outputs, low adoption, and increased compliance and security risk.
- In the digital workplace, better data annotation directly translates into better automation, search, analytics, and decision-making.
Read this article: : Top 6 AI-Powered Project Management Tools To Use In 2023
What Is a Data Annotation Company?
So, what is a data annotation company, really?
In plain terms, a data annotation company helps businesses turn raw, messy data into something AI systems can actually understand. They do this by labeling, tagging, and structuring data so machine-learning models know what they're looking at—and what to do with it.
On a day-to-day level, these companies aren't doing anything flashy. They're doing the unglamorous but critical work: reviewing datasets, applying consistent labels, checking for errors, removing bias, and validating accuracy.
Good annotation companies run strict quality checks, use multiple reviewers, and often combine human expertise with AI-assisted tools to keep accuracy high and mistakes low.
The type of data they work with depends on the use case, but it usually falls into four main categories:
- Text – emails, documents, chat logs, customer feedback, contracts
- Images – product photos, medical scans, satellite imagery
- Audio – voice recordings, call center conversations, voice assistants
- Video – security footage, training videos, autonomous systems
Now, you might be wondering why companies don't just do this themselves. The short answer?
Most teams underestimate how hard it is. Annotation takes time, focus, domain knowledge, and strong quality control.
Internal teams are usually stretched thin already, and small inconsistencies in labeling can quietly destroy model accuracy over time.
That's why businesses turn to a dedicated data annotation company. Not because they lack talent—but because annotation is a specialised, high-risk task where mistakes compound fast.
When AI is tied to real business decisions, "close enough" simply isn't good enough.
Types of Data Annotation (And When Each One Is Used)

Types of Data Annotation (And When Each One Is Used)
Not all data annotation is the same. The way data is labeled depends entirely on what the AI system is supposed to do.
A chatbot, a fraud-detection model, and an image recognition system all need very different kinds of annotated data.
This is where many teams go wrong—they treat data annotation as a single task instead of a set of specialised methods.
Here are the most common types of data annotation, explained without the technical fog.
Text Annotation
Text annotation is one of the most widely used forms, especially in enterprise tools and the modern digital workplace.
It helps AI understand written language instead of just reading words.
Common examples include:
- Named entity recognition (people, locations, organisations)
- Sentiment labeling (positive, neutral, negative)
- Intent detection (what the user is trying to do)
- Topic classification
This type of annotation powers chatbots, document search, email sorting, contract analysis, and internal knowledge systems.
Image Annotation
Image annotation teaches AI how to "see." Humans label objects or regions within images so models can recognise patterns visually.
Typical methods include:
- Bounding boxes around objects
- Image classification (labeling the entire image)
- Semantic segmentation (labeling every pixel)
- Landmark annotation for facial or medical analysis
You'll see this used in healthcare imaging, retail product recognition, security systems, and quality control tools.
Audio Annotation
Audio annotation focuses on sound rather than text or visuals. This is essential for voice-based systems and speech analytics.
Examples include:
- Speech-to-text transcription
- Speaker identification
- Emotion or tone detection
- Keyword spotting
Call centre analytics, voice assistants, and compliance monitoring all rely heavily on accurate audio annotation.
Video Annotation
Video annotation is more complex because it combines time, movement, and context. Instead of labeling a single moment, annotators tag events across frames.
Common approaches:
- Object tracking across video frames
- Action recognition (what's happening in the clip)
- Event detection
- Temporal segmentation
This type is widely used in security, autonomous systems, training simulations, and behaviour analysis.
AI-Assisted Annotation
This is where ai annotation comes into play.
Instead of humans starting from scratch, AI models suggest labels that humans review and correct.
The upside:
- Faster turnaround
- Lower costs at scale
The downside:
- AI introduces bias and errors if left unchecked
That's why experienced annotation companies use AI as an assistant—not a replacement. Human oversight is what keeps accuracy and trust intact.
Why the Type of Annotation Matters
Choosing the wrong annotation method doesn't just slow things down—it directly impacts model performance. Different AI use cases demand different annotation strategies, quality checks, and expertise.
The best data annotation companies don't just label data.
They help teams choose the right type of annotation from the start, so AI systems behave reliably in the real world—not just in controlled demos.
How Data Annotation Works (Without the Jargon)
This part sounds technical, but it's actually pretty straightforward once you strip away the buzzwords.
Data annotation follows a clear, repeatable flow—and when any step is rushed or skipped, the whole thing falls apart later.
Here's how it really works.
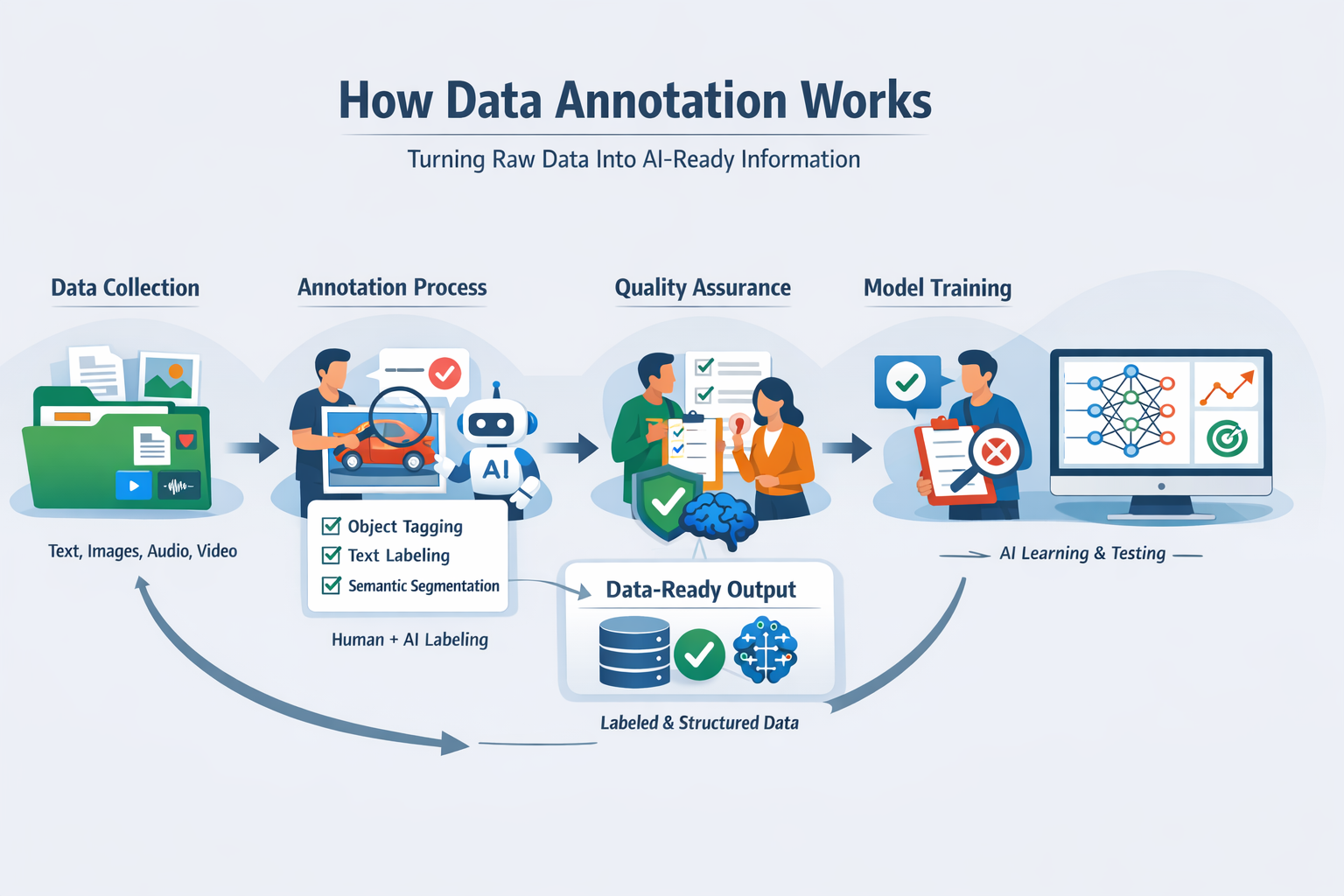
How Data Annotation Works (Without the Jargon)
Raw data collection
Everything starts with raw data.
This could be documents, emails, images, voice recordings, videos, or system logs.
At this stage, the data is basically useless to AI. It's unstructured, unlabeled, and full of noise.
Think of it as a box of unsorted puzzle pieces—nothing makes sense yet.
Labeling and tagging
This is the core of data annotation. Humans (sometimes supported by tools) label parts of the data so machines know what they're seeing.
For example:
- Marking entities in text
- Tagging objects in images
- Identifying intent in conversations
- Labeling outcomes or categories
This is where ai annotation often comes into play. AI can speed things up by suggesting labels, but humans still need to review, correct, and validate them.
Fully automated annotation sounds nice in theory, but in practice, it introduces errors fast—especially with nuanced or sensitive data.
Quality assurance
This step separates good annotation from sloppy annotation.
Multiple reviewers check the same data, inconsistencies are flagged, and edge cases are resolved.
Strong quality assurance is why professional annotation companies cost more—and why their results actually hold up in production.
Accuracy matters here far more than speed.
A fast dataset that's 85% correct will cause more damage than a slower one that's 98% accurate. Small errors multiply once models start learning from them.
Model training and iteration
Once the data is annotated, it's used to train AI models.
But this isn't a one-and-done process. Models are tested, mistakes are identified, and the data is refined again. Annotation improves, models improve, and the cycle repeats.
This is why annotation isn't just a setup task—it's an ongoing process. As AI systems evolve, so does the data they rely on.
The big takeaway?
Data annotation is less about speed and more about discipline.
The companies that treat it as a precision task—using AI to assist humans, not replace them—are the ones building AI systems that actually work in the real world.
Why Data Annotation Is Critical in 2026
By 2026, AI isn't a side project anymore. It's baked straight into how work gets done.
Inside the modern digital workplace, AI is reading documents, routing tickets, summarising meetings, powering search, scoring leads, and helping managers make decisions faster. And all of that only works if the data behind it has been annotated properly.
This is where reality hits. Poor data annotation doesn't just make AI a bit less accurate—it makes it unreliable. Bad labels introduce bias. Inconsistent tagging confuses models.
Missing context leads to wrong predictions. The result? AI tools that look impressive in demos but quietly fail in day-to-day use. When employees stop trusting the outputs, adoption drops and the whole investment starts to feel like a mistake.
There's also growing pressure from regulators and customers.
As AI becomes more involved in hiring, finance, healthcare, and internal decision-making, companies are expected to explain how their systems work and prove they're fair and secure.
If your training data was loosely labeled, poorly documented, or handled without proper controls, that's a compliance problem waiting to happen.
This is why experienced data annotation companies now put just as much emphasis on governance and auditability as they do on accuracy.

Then there's the competitive angle. In 2026, most businesses have access to similar AI models and tools.
What separates the winners from everyone else isn't the software—it's the quality of the data feeding it.
Companies that invest in better annotation build AI systems that are more accurate, more trustworthy, and more useful to real users. Everyone else ends up with generic tools that never quite deliver.
The takeaway is simple: data annotation has moved from a technical detail to a business-critical capability.
In a world where AI shapes productivity, decisions, and trust, the organisations with the best data foundations are the ones that pull ahead—and stay there.
Data Annotation vs AI Annotation: What's the Difference?
This is where a lot of confusion creeps in, because the terms get used interchangeably when they really shouldn't.
Data annotation and AI annotation are related, but they're not the same thing—and treating them as equals is how teams end up with unreliable models.
Human-led data annotation is exactly what it sounds like. Real people review data and apply labels based on context, judgment, and domain knowledge. Humans understand nuance.
They catch edge cases. They can tell when something is technically correct but practically wrong. That's why human annotation is still the gold standard for accuracy, especially in regulated or high-risk environments.
The downside? It's slower and more expensive at scale. Humans need training, clear guidelines, and quality checks. Cut corners here, and consistency disappears fast.
AI annotation, on the other hand, uses machine-learning models to automatically label data.
This works well for large, repetitive datasets where patterns are obvious. It's fast, cost-effective, and great for speeding up early stages of annotation.
But AI doesn't truly understand context—it predicts based on past patterns. When those patterns are flawed or incomplete, errors multiply quietly.
| Aspect | Data Annotation (Human-Led) | AI Annotation (Automated / Assisted) |
| Who does the work | Trained human annotators | Machine learning models |
| Accuracy | High accuracy, especially with complex or sensitive data | Varies; good for simple, repetitive patterns |
| Context & nuance | Strong understanding of intent, tone, edge cases | Weak with ambiguity, sarcasm, or domain nuance |
| Bias control | Humans can detect and correct bias | Can amplify existing bias if training data is flawed |
| Speed | Slower at scale | Very fast, especially on large datasets |
| Cost | Higher upfront cost | Lower cost at high volumes |
| Quality control | Multi-review workflows, human accountability | Depends heavily on model quality and oversight |
| Security risk | Lower when tightly controlled environments are used | Higher if data is widely processed without controls |
| Best used for | Regulated data, complex decisions, high-risk AI use cases | Large datasets, low ambiguity, early-stage labeling |
| Long-term reliability | High — results are explainable and auditable | Medium — requires frequent validation |
| Role in 2026 | Essential foundation for trustworthy AI | Acceleration layer, not a replacement |
This is why hybrid models dominate in 2026.
The smartest annotation workflows combine AI speed with human judgment.
AI suggests labels, flags obvious cases, and handles volume. Humans review, correct, and validate the results. You get efficiency without sacrificing trust.
The key is knowing when AI helps—and when it makes things worse.
AI annotation works well for clean, repetitive data with low ambiguity.
It struggles with sarcasm, emotion, sensitive language, medical nuance, legal context, and anything where a wrong label carries real consequences. In those cases, human-led data annotation isn't optional—it's essential.
Bottom line: AI can assist annotation, but it can't replace accountability.
The teams that get this right don't argue about humans versus machines—they design workflows where each does what it's best at.
Who Uses Data Annotation Companies?

Short answer: way more organisations than you'd expect.
Data annotation companies aren't just supporting flashy AI startups—they're quietly powering real-world systems that businesses rely on every day.
AI startups are the obvious ones. Most startups move fast and iterate constantly, which means they need large volumes of accurately labeled data without slowing down product development.
Building annotation teams in-house usually isn't realistic at this stage, so external experts fill that gap and help founders avoid training models on bad data early on.
Enterprise software vendors are another major group.
These companies are embedding AI into products used by thousands—or millions—of users. Think intelligent search, document automation, recommendations, or predictive analytics.
At this scale, inconsistent or biased data annotation becomes a reputational risk, not just a technical issue. That's why enterprises rely on structured, audited annotation workflows rather than ad-hoc internal labeling.
Then there are regulated industries like healthcare, finance, retail, and logistics. In healthcare, annotation supports diagnostics, medical imaging, and patient records.
In finance, it's used for fraud detection, risk scoring, and compliance monitoring. Retail uses annotation to power product recommendations and demand forecasting, while logistics relies on it for routing, inventory optimisation, and predictive maintenance. In all of these sectors, accuracy and security aren't "nice to have"—they're non-negotiable.
Finally, there are teams building AI features for the modern digital workplace. These are companies using AI to summarise meetings, classify documents, analyse conversations, automate workflows, and surface insights for employees.
The quality of those experiences depends entirely on how well the underlying data is annotated. When it's done right, AI feels helpful and trustworthy. When it's not, users disengage fast.
The common thread across all of these groups is the same: they don't use data annotation companies because it's trendy.
They use them because once AI starts influencing real decisions, guessing isn't acceptable—and getting the data right becomes a business priority, not just a technical task.
Read this article: : Top 6 AI-Powered Project Management Tools To Use In 2023
Top Data Annotation Companies to Know in 2026
When people ask about the top data annotation companies, they're usually looking for a simple list.
But in reality, what makes an annotation provider "top-tier" has less to do with brand recognition and more to do with how they operate behind the scenes.
In 2026, the best annotation companies aren't the loudest or the cheapest. They're the ones that consistently deliver accurate, secure, and scalable annotation without cutting corners.
Here's what actually separates strong providers from the rest.
What Qualifies a Top Data Annotation Company?
High-quality annotation is about consistency, not speed.
Top providers use multi-layer review processes, clear annotation guidelines, and domain-trained annotators.
They measure inter-annotator agreement, track error rates, and continuously refine labeling standards. Anything less, and model performance degrades fast.
Accuracy comes first
High-quality annotation is about consistency, not speed.
Top providers use multi-layer review processes, clear annotation guidelines, and domain-trained annotators.
They measure inter-annotator agreement, track error rates, and continuously refine labeling standards. Anything less, and model performance degrades fast.
Security isn't optional anymore
Leading annotation companies treat data security as a core capability, not an add-on.
That means strict access controls, encrypted environments, audit logs, and compliance with frameworks like ISO 27001, SOC 2, and GDPR. With sensitive training data moving through annotation pipelines, weak security is now a deal-breaker.
Scalability without chaos
It's easy to annotate small datasets. It's much harder to scale annotation to millions of records without quality slipping.
Top providers have mature workflows, tooling, and workforce management systems that allow them to scale up or down while maintaining accuracy.
Domain expertise matters
Generic annotation works for basic use cases, but it falls apart in healthcare, finance, legal, or enterprise software.
The strongest providers bring domain-trained annotators who understand context, terminology, and real-world implications—not just labeling instructions.
Well-Known Data Annotation Providers in the Market
Without ranking them, some widely recognised names in the space include Scale AI, Appen, Labelbox, and Samasource.
Each approaches annotation differently, with varying strengths across tooling, workforce models, industry focus, and pricing.
What matters more than the name is fit. A provider that works well for computer vision may not be right for enterprise document annotation or regulated data. That's why many organisations shortlist based on criteria, not reputation.
The "top" data annotation company isn't universal—it's contextual. In 2026, the best providers are the ones that align with your data sensitivity, accuracy requirements, industry complexity, and long-term AI goals.
Choosing based on price or speed alone is how teams end up retraining models, fixing bias, or rebuilding pipelines later.
Strong annotation doesn't draw attention to itself—but weak annotation always does.
How Data Annotation Companies Ensure Accuracy and Security
This is the part that separates serious data annotation companies from everyone else.
Anyone can label data. Very few can do it accurately, consistently, and securely at scale.
Here's how the good ones actually make that happen.
Accuracy Starts With Process, Not Tools
High accuracy isn't luck—it's engineered.
Professional annotation companies don't rely on a single annotator labeling data and calling it done.
Instead, they use multi-layer review workflows. That usually means one person labels the data, another reviews it, and a third resolves disagreements or edge cases. This reduces silent errors—the kind that don't show up until a model is already in production.
They also invest heavily in clear annotation guidelines.
Vague instructions lead to inconsistent labels, which confuse AI models.
Strong providers define edge cases upfront, document decisions, and update guidelines continuously as new patterns emerge.
Many also track inter-annotator agreement—a metric that shows how consistently different people label the same data. When agreement drops, it's a signal that the rules need tightening or retraining is required.
Human Expertise Where It Matters Most
Despite advances in ai annotation, humans are still essential—especially for complex or sensitive data. Experienced annotation companies use domain-trained annotators, not generic clickworkers.
That matters more than people realise.
A medical report, legal document, or financial transaction needs contextual understanding. A label that's technically correct but contextually wrong can quietly poison a dataset.
Human judgment is what catches those mistakes before they scale.
AI is used to assist—suggesting labels, handling repetitive cases—but humans remain accountable for final decisions.
Security Is Built Into the Workflow, Not Bolted On
On the security side, mature annotation companies treat training data like production data—because in many cases, it's just as sensitive.
Strong providers enforce role-based access controls, so annotators only see the data they absolutely need.
Environments are locked down, often using secure virtual workspaces with no local downloads, screenshots, or external access.
Data is typically encrypted in transit and at rest, with full audit logs tracking who accessed what and when. This is especially important when dealing with personal, medical, or financial information.
At an organisational level, reputable providers align with recognised standards like ISO 27001, SOC 2, and GDPR, not as marketing badges but as operational requirements.
These frameworks force discipline around data handling, retention, and incident response.
Continuous Monitoring, Not One-Time Checks
Accuracy and security aren't "set and forget."
The best annotation companies monitor error rates, reviewer feedback, and security controls continuously. When patterns shift—or risks increase—processes are adjusted in real time.
This is why experienced providers cost more than ad-hoc solutions. You're not paying for labels. You're paying for repeatability, accountability, and trust.
The bottom line is simple: in 2026, annotation quality and data security are inseparable.
If a company claims to deliver one without the other, that's a red flag—not a feature.
Red Flags to Watch For in a Data Annotation Vendor
Not all data annotation companies are created equal.
Some look great on the surface—slick websites, fast turnaround promises, low prices—but quietly introduce risk into your AI pipeline.
By the time problems show up, you're already retraining models or explaining bad outputs to stakeholders.
Here are the biggest red flags to watch for before you commit.
Lack of Transparency
If a vendor can't clearly explain how they annotate data, that's a problem.
You should know:
- Who is doing the annotation (humans, AI, or both)
- How accuracy is measured
- What quality checks are in place
- How disagreements or edge cases are handled
Vague answers like "we use proprietary processes" usually mean there is no real process. Transparency is a sign of maturity, not a liability.
Weak or Vague Security Practices
Security claims without specifics are a major warning sign.
If a provider can't explain:
- How access to data is restricted
- Whether environments are locked down
- How data is encrypted
- What compliance standards they follow
…you should assume security is an afterthought. In 2026, weak security in annotation workflows isn't just risky—it's negligent, especially when dealing with sensitive or regulated data.
Over-Reliance on Fully Automated AI Annotation
AI-assisted workflows are normal.
Fully automated annotation with no human oversight is not. Vendors that promise "100% automated labeling" for complex data are cutting corners.
AI is great for speed, but without human review it quietly introduces bias, mislabels edge cases, and amplifies errors.
If humans aren't accountable for final decisions, accuracy will degrade over time.
No Clear Quality Metrics
If a vendor doesn't track things like review rates, disagreement resolution, or consistency over time, quality is guesswork.
Strong annotation companies measure accuracy continuously and adjust when standards slip.
If the only metric they talk about is speed, you're paying for volume—not reliability.
Treating Annotation as a One-Time Task
Data annotation isn't a "set it and forget it" job. Models evolve.
Use cases change. New edge cases appear. Vendors who treat annotation as a one-off project won't support long-term AI performance.
Good partners expect iteration. Bad ones disappear after delivery.
Choosing the Cheapest Option
This is the most common mistake companies make.
Cheap annotation looks attractive—until you factor in retraining costs, model failures, biased outputs, or lost trust from users.
In annotation, you don't pay for labels. You pay for accuracy, consistency, and accountability. Cheap providers optimise for none of those.
Final Reality Check
Strong data annotation doesn't draw attention to itself. Weak annotation always does—usually when it's too late to fix cheaply.
If a vendor avoids specifics, oversells automation, or treats security as a checkbox, walk away. In 2026, the cost of getting data annotation wrong is far higher than the cost of choosing the right partner upfront.
How Data Annotation Fits Into the Future Digital Workplace
How Data Annotation Fits Into the Future Digital Workplace
By 2026, the digital workplace isn't just a place where people collaborate—it's a place where AI actively participates in the work.
And the quality of that participation depends directly on data annotation. Not models. Not tools. The data underneath them.
Here's how it shows up in real, everyday productivity.
AI-Powered Workflows That Actually Save Time
AI-driven workflows are meant to remove friction—routing requests, classifying documents, prioritising tasks, triggering approvals. But these workflows only work when the system understands what it's looking at.
Accurate data annotation teaches AI how to recognise intent, context, and outcomes.
Without it, workflows misfire: tickets get routed incorrectly, documents end up in the wrong queues, and automation creates more cleanup work than it saves.
When annotation is done right, AI workflows quietly speed things up instead of becoming another layer of friction.
Intelligent Search and Recommendations People Trust
Search is one of the most used—and most complained-about—features in the digital workplace. Employees don't want "smart" search. They want useful search.
Annotation helps AI understand relationships between documents, conversations, people, and topics.
That's what enables relevant search results, personalised recommendations, and content that surfaces when it's actually needed. When annotation quality is poor, search feels random.
When it's strong, employees stop hunting for information and start acting on it.
That's a direct productivity win.
Predictive Analytics That Support Better Decisions
Predictive analytics are increasingly used to forecast demand, spot risks, highlight trends, and support planning.
But predictions are only as reliable as the data they're trained on.
Clean, consistent annotation ensures AI understands historical patterns correctly. Weak annotation leads to misleading insights—numbers that look confident but don't reflect reality. In a business context, that's dangerous.
Good annotation turns analytics into decision support. Bad annotation turns it into noise.
Smarter Collaboration Tools, Not Noisy Ones
AI is now embedded in collaboration tools—summarising meetings, analysing conversations, suggesting next steps, and surfacing insights from chats and documents.
These features live or die based on how well the underlying data has been labeled.
Annotation helps AI distinguish signal from noise. It understands what matters, who's involved, and what actions are implied. When done well, collaboration tools feel helpful and unobtrusive.
When done poorly, they feel spammy, inaccurate, and easy to ignore.
The Business Reality
Data annotation isn't about making AI smarter in theory. It's about making work easier in practice.
In the future digital workplace, productivity gains won't come from adding more AI features. They'll come from AI that understands context, delivers accurate outputs, and earns employee trust.
That only happens when annotation is treated as a business foundation—not a technical afterthought.
In short: better annotation leads to better work, not just better models.
Wrapping up - Data Annotation Is No Longer Optional
If there's one thing to take away from all of this, it's that data annotation is no longer a behind-the-scenes technical chore
It's a foundation. Without it, AI systems don't just underperform—they mislead, introduce risk, and quietly erode trust across the organisation.
In 2026, businesses aren't struggling to access AI tools.
They're struggling to make those tools reliable in real-world conditions. And that gap almost always comes back to data quality. Poorly labeled data leads to weak predictions, biased outcomes, and AI features that employees stop using because they don't trust the results.
That's why choosing the right data annotation company matters so much. A good partner doesn't just deliver labels—they bring structure, discipline, security, and accountability to your AI pipeline.
They help you avoid costly rework, compliance headaches, and the slow loss of confidence that comes from AI that "kind of works."
The final reality is simple and a bit uncomfortable: AI success is really data quality success. The companies that understand this in 2026 won't be the ones chasing the newest models.
They'll be the ones investing in clean, accurate, and secure data from the start—and quietly pulling ahead while everyone else tries to fix problems later.
Most Popular Posts

Effective communication among team members is vital for the productivity and success of any organization. Surprisingly, 60% of companies lack a long-term internal communication strategy, which p...


Businesses thrive on communication for efficiency, productivity and accomplishment. When the right information is passed from the right designation in the organization, it promotes positivity an...
Categories
Blog
(3052)
Business Management
(384)
Employee Engagement
(227)
Digital Transformation
(197)
Growth
(145)
Intranets
(137)
Internal communications
(103)
Remote Work
(63)
Sales
(53)
Collaboration
(48)
Customer Experience
(32)
Culture
(30)
Project management
(29)
Knowledge Management
(28)
Leadership
(20)
Comparisons
(9)
News
(1)

Related Posts

Launching a great digital workplace platform is only half the battle. If visitors land on your website and can't immediately understand what your software does, who it's designed for, or why it's different from the dozens of alternatives on the marke...

Selecting the best virtual data rooms for M&A is one of the most important decisions you'll make during a merger, acquisition, fundraising round, or business sale. While many platforms promise secure document sharing, not every virtual data...

Growing a small business is exciting—but scaling it successfully is where many businesses struggle. According to the U.S. Small Business Administration (SBA), around 50% of small businesses survive beyond five years, highlighting just how diffi...

Let's be honest—most AI projects don't fail because the technology isn't good enough. They fail because businesses jump straight into buying AI tools without first figuring out what problem they're actually trying to solve. In fact, accor...

Choosing the right infrastructure for an on-premises intranet is one of the most important decisions you'll make before deployment, yet it's often overlooked until performance issues begin to appear. At first glance, VPS hosting vs dedicated ho...


Jill Romford
I am a digital nomad, lover of exploring new places and making friends.
I love to travel and I love the internet. I take pictures of my travels and share them on the internet using Instagram.
Traveler, entrepreneur, and community builder. I share my insights on digital marketing and social media while inspiring you to live your fullest life.
Ready to learn more? 👍
One platform to optimize, manage and track all of your teams. Your new digital workplace is a click away. 🚀
Free for 14 days, no credit card required.